Ниже — проведу детальный разбор вопрос и ответов из этого интервью по System Design:
Mock-собеседование от Team Lead из Ozon секции по языку Golang на платформе it-interview.io.
Общий вывод: Кандидат (Александр) показал очень высокий уровень подготовки.
Он системно подошел к задаче: собрал требования, провел все необходимые расчеты, предложил продуманную архитектуру с разделением трафика чтения и записи, затронул вопросы масштабирования, отказоустойчивости и генерации уникальных ключей.
Основные замечания касаются тайм-менеджмента (повторы) и изначально неверного выбора ключа шардирования, который, однако, был вовремя исправлен.
Вопрос 1: Уточнение функциональных требований
- Вопрос собеседующего: Что именно должен делать сервис? Классический редирект или просто возвращать ссылку? Нужна ли аутентификация?
- Ответ интервьюера (в интерпретации): Мы будем делать сервис, который по длинной ссылке возвращает короткую. По GET-запросу на короткую ссылку мы должны вернуть длинную (без редиректа). У ссылок есть срок хранения. Пользователи могут задавать кастомные имена (alias). Аутентификация есть, но мы ее не проектируем, просто обозначим на схеме. Нужен rate limiting и базовая аналитика (количество переходов).
- Анализ ответа: Верно. Кандидат четко отделил «классический» сценарий от требуемого (возврат ссылки, а не редирект), что важно для проектирования API. Он правильно вынес аутентификацию за скобки, но учел ее наличие.
- Полный правильный ответ: Наш сервис будет предоставлять два основных API:
POST /shorten: принимаетlong_urlи опциональныйcustom_alias, возвращаетshort_key. Требует аутентификации.GET /{short_key}: принимает короткий ключ, возвращает оригинальную длинную ссылку (200 OK) или ошибку (404/410), если ссылка не найдена или истекла.
Также нам необходимы: ограничение частоты запросов (rate limiting) для защиты API и сбор аналитики по количеству обращений к каждомуshort_key(например, для последующего построения графиков).
Вопрос 2: Сбор нефункциональных требований и оценка нагрузки
- Вопрос собеседующего: Какая предполагается нагрузка? Какое соотношение чтения и записи? Требования к задержкам и доступности?
- Ответ интервьюера (в интерпретации): Будем считать от количества создаваемых ссылок: 100 млн новых ссылок в месяц. Соотношение чтения к записи — 100:1 (т.е. 10 млрд переходов/чтений в месяц). Хранение — 1 год (позже скорректировано на 10 лет по совету интервьюера). Задержка на чтение — 1 мс (очень жесткое требование). Доступность — высокая, система должна масштабироваться.
- Анализ ответа: Верно. Кандидат использует подход «от записи», что логично для такого сервиса. Он корректирует цифры подсказки интервьюера, что показывает гибкость. Выбор метрик (1 мс, высокая доступность) задает тон для проектирования высоконагруженной системы.
- Полный правильный ответ: Исходя из требования в 100 млн новых ссылок в месяц и соотношении Read:Write = 100:1, мы получаем:
- Запись: ~100 млн операций в месяц → (100e6 / (30*86400)) ≈ ~40 RPS (запросов в секунду). Пиковый можно умножить на 2-3.
- Чтение: ~10 млрд операций в месяц → ~4000 RPS.
Система критична к задержкам на чтение (target 1 мс), так как это пользовательский опыт. Доступность должна быть высокой (цель 99.95% – 99.99%), так как сервис используется другими системами. Масштабируемость обязательна, так как нагрузка может расти.
Список требований:

Вопрос 3: Схема данных и расчет объема хранилища
- Вопрос собеседующего: Как будет выглядеть модель данных? Какой объем данных мы будем хранить?
- Ответ интервьюера (в интерпретации): Таблица/коллекция
linksбудет содержать:long_url(256 байт),short_key(8 байт, если использовать base64),user_id(10 байт),created_at(6 байт). Итого ~300 байт на запись. При 100 млн записей в месяц и сроке хранения 10 лет, общий объем: 100 млн * 12 месяцев * 10 лет * 300 байт ≈ 3.6 ТБ. - Анализ ответа: Отлично. Кандидат не просто называет цифры, а объясняет, из чего они складываются. Расчет объема хранилища (3.6 ТБ за 10 лет) показывает, что данные не являются проблемой и могут поместиться на относительно небольшом кластере серверов, что оправдывает выбранные подходы к шардированию.
- Полный правильный ответ: Для хранения метаданных ссылок нам потребуется примерно 300-350 байт на запись (с учетом индексов и служебной информации). При 100 млн новых ссылок в месяц и хранении в течение 10 лет, общий объем данных составит около 4 ТБ. Это довольно скромный объем, что позволяет нам рассматривать относительно простые решения для шардирования. Трафик: запись ~ 40 RPS * 300 байт ≈ 12 КБ/с (входящий), чтение ~ 4000 RPS * 300 байт ≈ 1.2 МБ/с (исходящий).
Вопрос 4: Проектирование высокоуровневой архитектуры
- Вопрос собеседующего: Предложите High-Level Design.
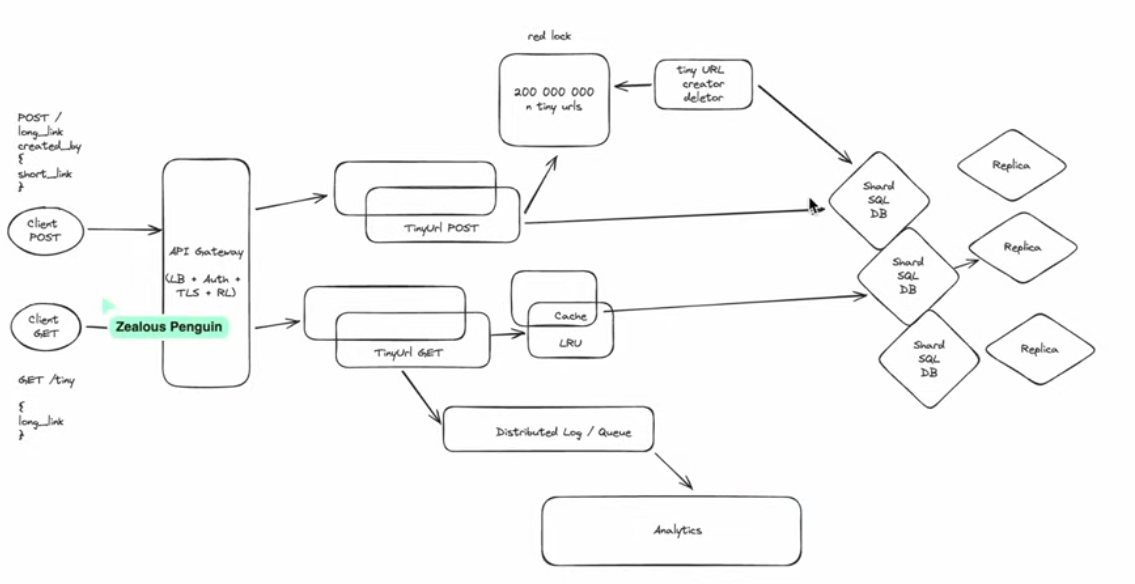
- Ответ интервьюера (в интерпретации): Рисуем клиентов (разделяем на читающих и пишущих). Далее API Gateway (балансировка, TLS, аутентификация). За ним разделяем сервисы на TinyURL Creator (Post) и TinyURL Fetcher (Get) для независимого масштабирования. Далее — шардированная БД (SQL) с репликами для отказоустойчивости. Для чтения добавляем кэш (Redis) перед БД по стратегии LRU.
- Анализ ответа: Верно и очень хорошо. Кандидат принимает ключевое архитектурное решение — разделение трафика чтения и записи на разные сервисы. Это позволяет оптимизировать стоимость и ресурсы (держать много инстансов для Get и мало для Post). Добавление кэша для чтения — обязательный элемент для достижения задержки в 1 мс.
- Полный правильный ответ: Наша High-Level архитектура будет состоять из:
- Клиенты и API Gateway: Единая точка входа для балансировки нагрузки, терминирования TLS, rate limiting и аутентификации.
- Сервис записи (Post Service): Отвечает за генерацию и сохранение коротких ссылок. Масштабируется горизонтально, но требует меньше инстансов.
- Сервис чтения (Get Service): Отвечает за обработку запросов на получение длинной ссылки по короткому ключу. Масштабируется агрессивно для обработки высокого RPS.
- Слой кэширования (Redis Cluster): Распределенный кэш перед БД для обеспечения задержки чтения <1 мс. Используем стратегию Cache-Aside.
- Слой данных (Sharded SQL Database): Основное хранилище. Шардирование необходимо для распределения нагрузки и объема данных. Репликация (replicas) — для отказоустойчивости и распределения нагрузки чтения.
Вопрос 5: Выбор ключа для шардирования
- Вопрос собеседующего: По какому ключу вы будете шардировать данные в БД?
- Ответ интервьюера (в интерпретации): Первоначально: По хэшу от
long_url. После уточнения: Понял ошибку, нужно шардировать поshort_key, так как именно он приходит в запросе на чтение (GET /{short_key}), и нам нужно быстро определить, на каком шарде искать данные. - Анализ ответа: Верно (после коррекции). Кандидат демонстрирует умение слышать собеседника и исправлять ошибки на лету. Это очень ценный навык на интервью. Изначально неверный выбор ключа — распространенная ошибка.
- Полный правильный ответ: Ключом для шардирования должен быть
short_key. Рассмотрим потоки данных:- Запись: Мы создаем
short_key-> мы вычисляем его хэш -> определяем шард -> пишем данные. - Чтение: Клиент приходит с
short_key(GET /{short_key}) -> мы вычисляем его хэш -> определяем шард -> идем в кэш или напрямую в БД на нужный шард.
Шардирование поshort_keyгарантирует, что все операции с конкретной ссылкой будут направлены на один и тот же шард, и нам не нужно делать broadcast-запросы во все шарды для поиска данных.
- Запись: Мы создаем
Вопрос 6: Генерация уникальных коротких ссылок (ключей)
- Вопрос собеседующего: Как вы будете гарантировать уникальность
short_keyна всех шардах? Если два сервиса-создателя одновременно сгенерируют одинаковый ключ для разных ссылок, возникнет коллизия. - Ответ интервьюера (в интерпретации): Использовать хэш от
long_urlнебезопасно из-за коллизий при обрезке до 8 символов. Предлагаю вынести генерацию в отдельный сервис/хранилище (например, Redis), которое будет выдавать заранее сгенерированные уникальные ключи, используя распределенные блокировки (Redlock) для обеспечения атомарности выдачи. - Анализ ответа: Верно, но сложно. Кандидат предлагает рабочее решение (pre-generated keys + distributed locks), но оно может стать узким местом и добавить лишнюю сложность. Существуют более простые и распространенные паттерны.
- Полный правильный ответ: Есть несколько подходов:
- Глобальный генератор ID (Snowflake ID): Использовать распределенный генератор уникальных ID (как Twitter Snowflake), который выдает 64-битные числа. Затем эти числа можно закодировать в base62, чтобы получить короткую строку. Это исключает коллизии на уровне генерации.
- База данных + Hash + Probabilistic approach: Взять хэш от
long_url+ соль. При попытке вставки в БД по уникальному индексу на колонкеshort_keyможет произойти ошибка дубликата. В этом случае сервис повторяет попытку с новой солью. Это очень распространенный и надежный подход (особенно для не слишком высоких RPS на запись).
Предложенный вами подход с предвыделенными ключами в Redis также рабочий, но он требует поддержки консистентности этого пула и может быть сложнее в реализации. Я бы, наверное, остановился на подходе с Snowflake-like генератором или подходе «попробуй еще раз» (retry on duplicate key), так как 40 RPS на запись позволяют это сделать без проблем.
Вопрос 7: Идемпотентность создания ссылки
- Вопрос собеседующего: Что будет, если пользователь дважды отправит запрос на создание одной и той же длинной ссылки? Мы создадим два разных коротких ключа или должны вернуть существующий?
- Ответ интервьюера (в интервью этот вопрос был задан в самом конце, но логически относится к функциональности).
- Ответ интервьюера (в интерпретации): Не был явно проработан в основной части.
- Анализ: Кандидат упустил этот момент в требованиях. Это важный функциональный нюанс.
- Полный правильный ответ: Нам нужно решить вопрос идемпотентности. Есть два подхода:
- Всегда создавать новый ключ: Это просто, но может привести к захламлению хранилища дублями.
- Идемпотентность на стороне сервера: Если ссылка для данного пользователя уже существует, возвращать существующий
short_key. Для этого можно использовать комбинацию(user_id, long_url)как ключ для проверки дубликатов. Это удобно для пользователя и экономит место. Я бы предложил реализовать именно этот подход, добавив уникальный композитный индекс в БД.
Вопрос 8: Анализ точек отказа и повторное использование кода
- Вопрос собеседовавшего (в конце): Где у нас точки отказа?
- Ответ интервьюера (в интерпретации): Обсудили отказ шарда, мастера БД, узлов кэша, сервисов. Предложили репликацию и механизмы перевыборов мастера.
- Анализ: Верно. Кандидат понимает основные принципы обеспечения отказоустойчивости.
- Замечание интервьюера по тайм-менеджменту: Кандидат несколько раз подробно рассказывал про шардирование и репликацию в разных частях интервью.
- Полный правильный ответ (в части коммуникации): «Как мы обсуждали на этапе проектирования хранилища, для обеспечения отказоустойчивости мы используем репликацию мастер-реплика для каждого шарда. В случае отказа мастера одна из реплик будет повышена до мастера. Здесь в этом flow применим тот же самый подход, поэтому я не буду повторять детали, если вы не против.» Такой подход экономит время и показывает, что кандидат держит в голове целостную картину.
Фидбэк от интервьюера
[[ Отзыв о кандидате ]]- Александр во время собеседования показал себя хорошо.
- Показал себя как специалист способный анализировать предметную область и способный подстраиваться под новые требования.
- В качестве системы для проектирования был выбран URL Shortnet (сокращатель ссылок).
- Кандидат собрал все требования, реализовал верхнеуровневый дизайн и постепенно углубился до компонентов.
- Из плюсов еще могу отметить что разделил трафик на чтение и на запись и проработал оба потока данных. Проработал систему хранения, масштабирования и отказоустойчивости.
- В ходе интерью из за того что сразу не спроектировал API ошибся с выбором ключа для шардирования данных.
- Но после того как спроектировал две API ручки быстро сообразил в какую сторону необходимо смотреть.
- Так же не до конца раскрыл как именно будет генерироваться уникальная ссылка.
- Не определились со словарем и полным алгоритмом.
- По коммуникациям приятный в общении, рассудительный.
- Все предположения обосновывает и рассуждает в слух, что дает понять в какую сторону движется.
- Из рекомендаций можно посоветовать следить за таймингом, чаще просматривать первоначальный требования и не повторяться на тех моментах, которые уже были озвучены ранее.
(с) Валерий Бабушкин. System Design. Карьера в IT. Karpov courses. Яндекс алгоритмы.
Нет Ответов